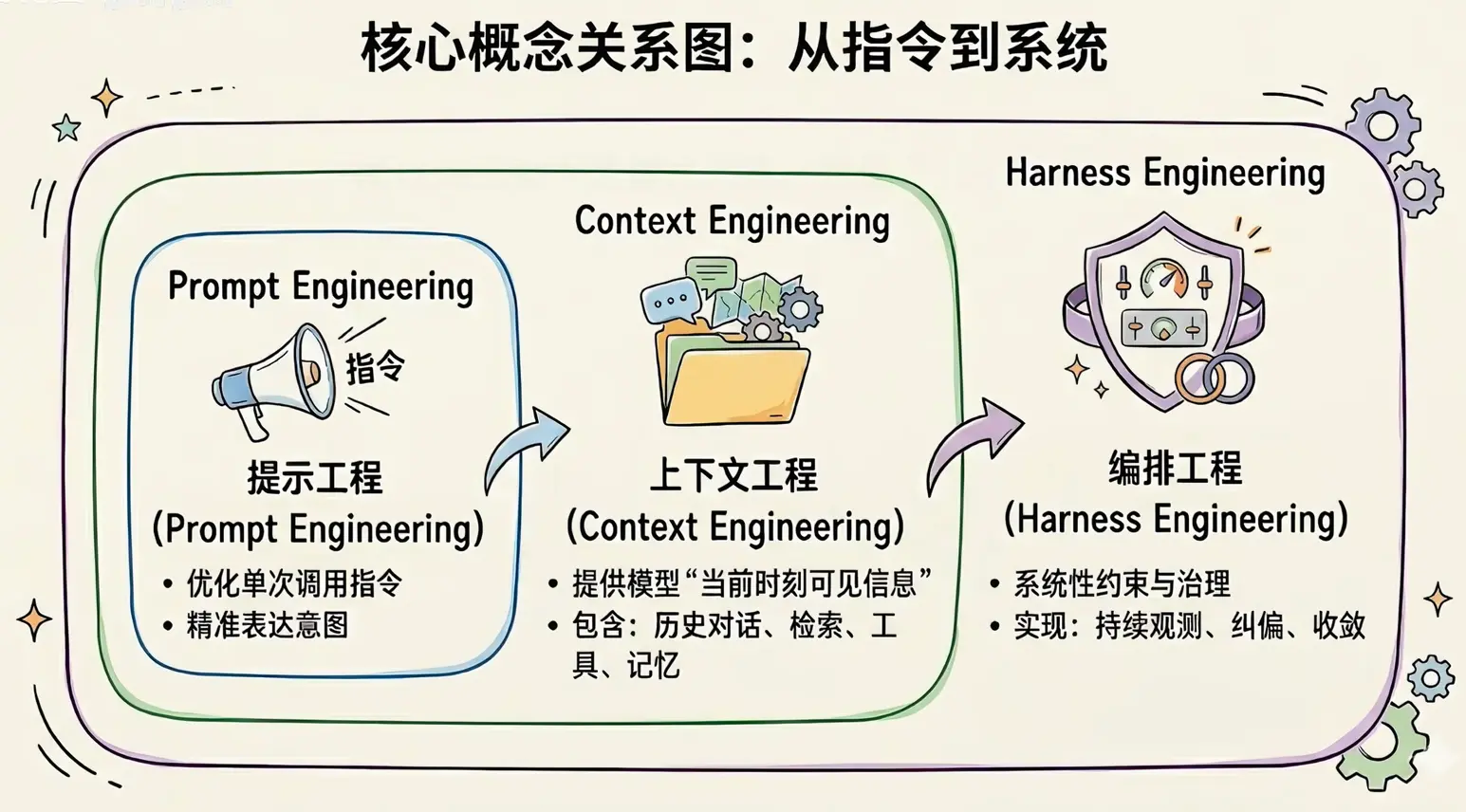
AI的三次重心迁移
关于AI发展的趋势,略有小想。
Prompt Engineering
提示词阶段 即模型有没有听懂你在说什么?
总结和提炼关键词是现在大部分人使用AI的方向,这一阶段大家相信模型不是不会,是你没把问题描述清楚。
于是通过角色设定、风格约束、few-show示例、分布引导、输出格式、拒答边界这几个方面,去塑造一个局部概率空间。
这一阶段
擅长的是澄清任务、约束输出、激发模型已有的能力,
而不擅长凭空补齐缺失知识、管理大量动态信息、处理长链路动态变化。
即 Prompt 解决的是表达的问题,不是信息问题。
Context Engineering
内容阶段 即模型有没有拿到足够且正确的信息?
AI Agent火了后,模型开始不止要回答问题,还要进入到真实的工作环境里面做事情。
最近很火的小龙虾就是一款免费的开源AI代理(AI Agent)软件,因标志为红色龙虾,故而得名。
它不仅需要多轮对话,调浏览器、写代码、数据库这些工具,还要在多个步骤之间传递中间结果,还要根据外部的反馈不断调整计划。
此时AI的任务就不是一次回答对不对,而是整条任务链路能不能跑通。
比如 你不是简单得问一句帮我总结这篇文章,二是让它完成一个具体真实的任务,即分析文档需求 ⇒ 找出潜在风险 ⇒ 结合历史意见 ⇒ 生成反馈稿。
这时候,你就会发现只调优提示词已经没法解决了。 至少要拿到当前的需求文档历史评审记录、相关规范、输出对象是谁、语气应该怎么调、当前目标、已经分析出来中间结论的对象是谁等等。
即这阶段的核心就是AI未必知道,所以系统就要在AI需要的时候把正确的信息送进去
这里面的Context并不是狭义上的几段背景资料,而是包括了所有会影响AI当前决策的信息总和。
包括用户输入、检索结果、工具返回、当前任务状态、中间产物、系统规则、安全约束、其他Agent传过来的结构化结果。就会发现上一阶段的Prompt只是Context的一部分。
自然而然的,此时差距的造成往往不会是AI模型,而是上下文供给的机制,也就是系统。
RAG 就是一个典型的实践。
检索增强生成(RAG)是指对大语言模型输出进行优化,使其能够在生成响应之前引用训练数据来源之外的权威知识库。
模型参数里面没有的知识,要怎么在运行的时候补进去呢?
思路就是先检索再注入,最后模型基于已有信息回答。
而成熟的Context Engineering关注的远不止检索这一点,它关注的是一整条线。
文档怎么切块 ⇒ 结果怎么排序 ⇒ 长文怎么压缩 ⇒ 历史对话:原文VS摘要 ⇒ 工具返回:要不要全部暴露给模型? ⇒ Agent间:传原文/摘要/结构化字段
最近很火的Agent Skills 本质上也是Context Engineering的高级实践。
如果你上来就把所有的工具、说明和参数都给模型,理论上模型会知道的更多,但是实践往往会一团糟。
因为上下文窗口是非常稀缺的资源,过多的Context参与只会拉低各个Context的权重,从而导致注意力涣散。
而此时 Skills 采用的一种渐进式披露,便应运而生。
这个思路就说明了 上下文优化重要的不是给的多,而是按需给(只提供当前任务必须的信息)、分层给(从元信息到详细内容的渐进展开)、在正确的时机给(在触发特定能力时动态加载)。
接着现在又发现了更麻烦的问题
就算信息给对了,模型也不一定能稳定执行对
完美的信息输入等待你的可能是混乱的执行过程。
它可能计划做的很好⇒执行跑偏了,掉了工具⇒理解错了返回结果。
然后一步错步步错,在很长的链路里已经越跑越偏。
可是系统却没有发现,状态完全失真,那结果可想而知。
这时候我们就会发现:
提示词和优化信息供给其实解决的都是输入侧的问题,执行侧中,连续行动的不确定性却没有监督、约束和纠偏。
而这便是下一阶段的方向 Harness Engineering。
Harness Engineering
执行阶段 即在正式执行中,能不能持续作对?
Harness 本意是缰绳、马具 约束的意思。
放在AI系统里面就是当模型从回答问题走向执行任务时,系统不止要负责喂信息,还要能驾驭整个过程,这个就是Harness的出发点。
前两个阶段是怎么让AI更会想,这一阶段是让模型别跑偏、跑得稳、出了错还能拉回来。
目前的方向重点已经不是”把话说明白”和”资料齐不齐了”,而是有没有一套持续观测、持续纠偏、持续验收的机制。
Langchain Engineer给Harness下了一个定义
Agent = Model + Harness
Harness = Agent - Model
即在一个agent系统中,除了模型本身以外,所有决定它能不能稳定交付的东西,都可以算进Harness。
有人把成熟的Harness分成了六层。
| Layer | Name |
|---|---|
| Layer 6 | 约束校验与失败恢复 |
| Layer 5 | 评估与观测 |
| Layer 4 | 状态与记忆 |
| Layer 3 | 执行编排 |
| Layer 2 | 工具系统 |
| Layer 1 | 上下文管理 |
1.上下文管理
站在Harness视角重新看Context。
模型能不能稳定发挥,很多时候不取决于它”聪不聪明”,而取决于它看到了什么。 这便是harness的第一职责 让模型在正确的信息边界内思考。
角色的目标和定义
AI要知道自己是谁、任务是什么、成功标准是什么。
信息的裁剪和选择
上下文不是越多越好,而是越相关越好。
结构化组织
固定的规则放在哪、当前的任务放在哪、运行状态放在哪、外部的证据放在哪,最好分层清楚。因为信息一旦乱掉,模型就很容易漏重点、忘约束,甚至自我污染。
2.工具系统
若没有工具,ai本质上只是一个文本预测器。会解释、会总结、会推理,但接触不到真实的世界。
Harness在这里并不是简单的把工具挂上去,而是要解决三个问题
给它什么工具
工具太少,能力不够;工具太多,模型会乱用。
什么时候该调用工具
本来不需要查的时候别硬查,该查证的时候也别硬答。
结果怎么重新喂回去
搜索回来的几十条结果,不应该原封不动地塞回去,而是要提炼、筛选、保持和任务的相关性。
3.执行编排
解决核心问题:模型下一步该干什么?
很多agent的问题不是某一部不会,而是不会把各个步骤串起来。整个过程想到哪里做到哪里,最后交出来一堆半成品。
所以一个完成的任务链条应该包括这样的路线: 理解目标 ⇒ 判断信息够不够 ⇒ 不够就去补 ⇒ 基于结果继续分析 ⇒ 生成输出 ⇒ 检查输出 ⇒ 不满足要求就重新修正或者重试
这里Harness扮演的角色和人在工作时所用的经验很相似.
4.状态与记忆
没有状态的Agent,每一轮都像失忆。
即 Harness 要管理状态。
当前任务状态
步骤一已完成 ⇒ 步骤二进行中
会话中间结果
刚才查到的aip文档地址是”https://…”
长期记忆与偏好
“用户喜欢用python写脚本”、”代码风格要求带类型提示”
5.评估与观测
很多系统不是生成不出来,而是生成完后,不知道自己做得好不好.
若没有这一层,agent就会长期处在一种自我感觉良好的状态。
这一层通常包括输出验收、环境测试、自动测试、日志和指标、错误归因。 让系统不仅要会做,还要知道自己做得对不对。
6.约束校验与失败恢复
在真实环境里,失败是常态。搜索不准、API超时、文档格式乱、工具权限不够、模型误解任务都可能导致整个任务的崩溃.如果没有恢复机制,那么agent就只能重新来过.
所以一个成熟的Harness一定要有三件事
约束
哪些能做、哪些不能做。
校验
输出之前 输出之后要怎么检查
恢复
失败后, 怎么重试、切路径、回滚到稳定的状态
其实后面还有两三个案例 脑子清醒着再写吧
分别是Langchain、OpenAI、Anthropic的实践。
Anthropic是做游戏、数字音频工作站
这其中发现两个严重的问题
上下文焦虑
随着工作时间的拉长 模型就开始丢细节、丢重点 到最后自己会感觉装不下 然后草草收尾。
目前常规的解法就是context compaction 即把历史压缩一下继续跑 但也只是隔靴搔痒 时间一长还是会一如从前
激进的解法会 context reset 不是在原上下文中做文章,而是换了另一个agent专门负责总结。
这个思路就像是工程里面遇到内存泄漏不是去简单得清缓存 而是直接重启整个进程 在恢复状态。
自评失真
即模型自己给自己评分 就会导致过于自我感觉良好。尤其是在设计、体验、产品完成度这类没有完整答案的问题,偏差就会更明显。
而解决的思路就是 干活的和验收的分开 分成三个
Planner 负责把模糊的需求扩展成完整的规格
Generator 负责逐步的去实现
Evaluator 则是像真正的QA一样 去真实的测试。且不是只看代码 还会去操作页面、看交互情况、检查实际的结果。这是一个带具体环境的验证。
生产和验收必须分离这一思路 只要评估者足够独立 则检验机制才能发挥其作用
生成 ⇒ 检查 ⇒ 修复 ⇒ 再检查 的这样一个循环
OpenAI
设计目录索引 防止一开始给模型大量信息和工具从而导致注意力丢失